Design Description
Bypassing
Bypassing is implemented across multiple pipeline stages to resolve data hazards, minimizing the need for stalling. Bypassing implementation is having some issues, but it was planned to go as follows:
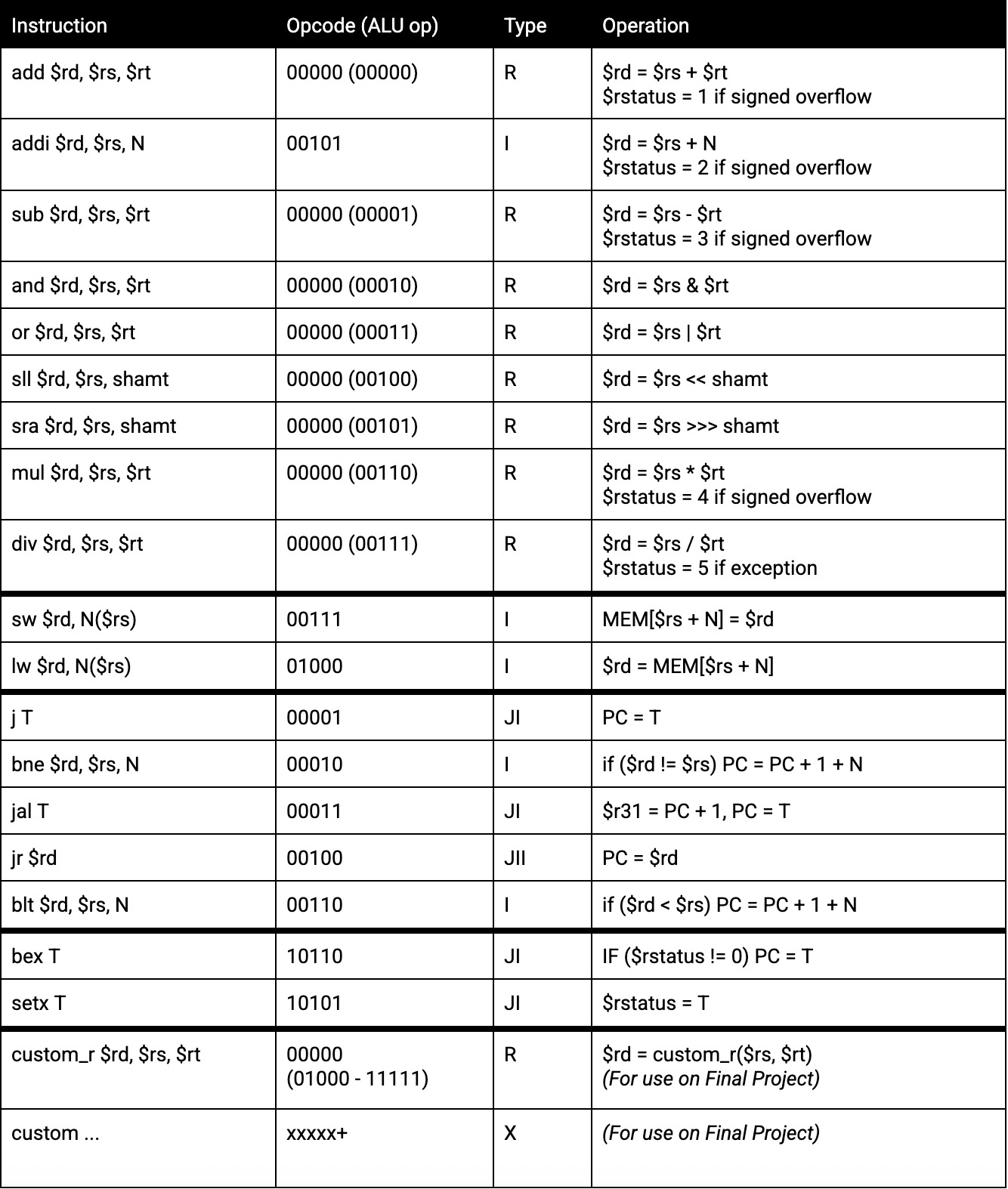
- ALU Operand Bypassing: Logic in place bypasses results from the Memory/Write (M/W) and Execute/Memory (X/M) pipeline stages to the ALU in the Decode/Execute (D/X) stage. For example, operandA_bypass and operandB_bypass determine if data from previous stages should override default values for ALU operations.
- Mult/Div Bypassing: Bypasses occur if a mult/div operation result is not yet ready; the pipeline will stall until the operation is completed. However, when available, bypassing will use the result to avoid pipeline delays.
- Branch Bypassing: For branch instructions (bne, blt, etc.), bypassing ensures that the correct values are available from the relevant stages without introducing additional cycles. This is implemented using conditions that ensure the latest values are always used in ALU comparisons.
Stalling
Stalling logic is used to handle load-use data hazards and situations where mult/div instructions require multiple cycles. For my processor, I have multiple instances of stalling logic:
- Load-Use Stall: A stall occurs if an instruction in the Decode stage needs data from a load instruction in the Execute stage, which isn’t yet available. This is detected by checking if a load (lw) instruction in the Execute stage has a destination register that matches the source register of the instruction in the Decode stage.
- Mult/Div Stall: If a mult/div operation is currently in progress (multdiv_busy), the pipeline stalls to ensure the operation completes before any subsequent dependent instructions proceed.
- Branch Delay: The pipeline stalls when a branch instruction is detected, allowing the branch target address to resolve correctly without incorrect predictions. The branch mux control feeds into my 'branch_taken' signal, which is input as an input that is used in the ternary operator for the instruction in on the F/D pipeline and overrides the PC enable on Fetch in order to ensure the instruction isn't overwritten when multdiv_stall, data_hazard, or stall signals occur.
Optimizations
The processor uses a 5-stage pipeline (Fetch, Decode, Execute, Memory, Write) to improve instruction throughput and reduce the number of cycles required to execute instructions. This allows for multiple instructions to be processed simultaneously, improving overall performance. Specific optimizations include
- Pipeline Register Enabling: Each pipeline register (like FD_pipeline_reg, DX_pipeline_reg) has an enable signal to prevent unnecessary updates, especially during stalls and flushes.
- Bypassing Logic: Extensive use of bypassing reduces the frequency of stalling, allowing the pipeline to maintain high throughput. For example, instructions that do not rely on recent data can execute without waiting for the full write-back stage.
- Conditional Operand Selection: Operand selection logic for the ALU includes immediate values, register values, and branch targets, based on instruction type and opcode, which streamlines handling of branching and immediate-type instructions.
- Exception Handling: Exceptions are handled by routing special values to the write-back stage, ensuring exceptions do not disrupt the pipeline flow unnecessarily, with specific handling for overflow and mult/div exceptions.